引言:AI Agent的“落地之困”
人工智能(AI)的浪潮正以前所未有的速度席卷各行各业,其中,AI Agent(智能体)被寄予厚望,有望成为重塑业务流程的革命性力量。然而,理想与现实之间存在巨大鸿沟。一篇广受关注的行业分析[1] 指出,高达95%的AI Agent项目在生产环境中遭遇失败。失败的核心原因并非大语言模型(LLM)不够智能,而是其周围缺乏坚实的“脚手架”——即完善的上下文工程、治理与信任机制、架构化的内存设计等。
本文旨在深入探讨这“5%的成功秘诀”,并结合DataFocus这一智能搜索式BI解决方案的技术特性,提出一套可落地的数据分析智能体设计策略。我们将阐述如何将前沿的AI Agent理念,通过DataFocus的现有功能转化为企业可直接应用的生产力工具,从而跨越从“原型”到“产品”的死亡之谷。
背景分析:解码AI Agent成功的关键支柱
根据《What Makes 5% of AI Agents Actually Work in Production》[1]一文的洞察,成功的AI Agent系统远不止于“提示词工程”。真正的护城河建立在模型之下的庞大冰山——即围绕模型的工程化体系。文章将成功的关键要素归纳为以下几个核心支柱:
1. 上下文工程 (Context Engineering): 真正的战场
多数团队将产品与提示词混为一谈,但成功的团队早已将重心转向上下文工程。这并非简单的“提示词黑客技术”,而是关于如何为LLM精准筛选、组织和验证信息。文章指出,精良的检索增强生成(RAG)通常比模型微调更有效,但多数RAG系统过于初级,易导致模型困惑或信息不足。先进的上下文工程应包含:
- LLM原生特征工程: 将上下文剪枝、验证、可观测性视为特征工程的一部分,使其可版本化、可审计、可测试。
- 语义与元数据分层: 结合向量搜索(语义层)与基于文档类型、时间戳、权限的元数据过滤,确保检索到的不仅是“相似内容”,更是“相关的结构化知识”。
- 对Text-to-SQL的现实认知: 承认自然语言的模糊性,通过构建业务术语表、查询模板和验证层来解决,而非直接将数据库模式抛给模型。
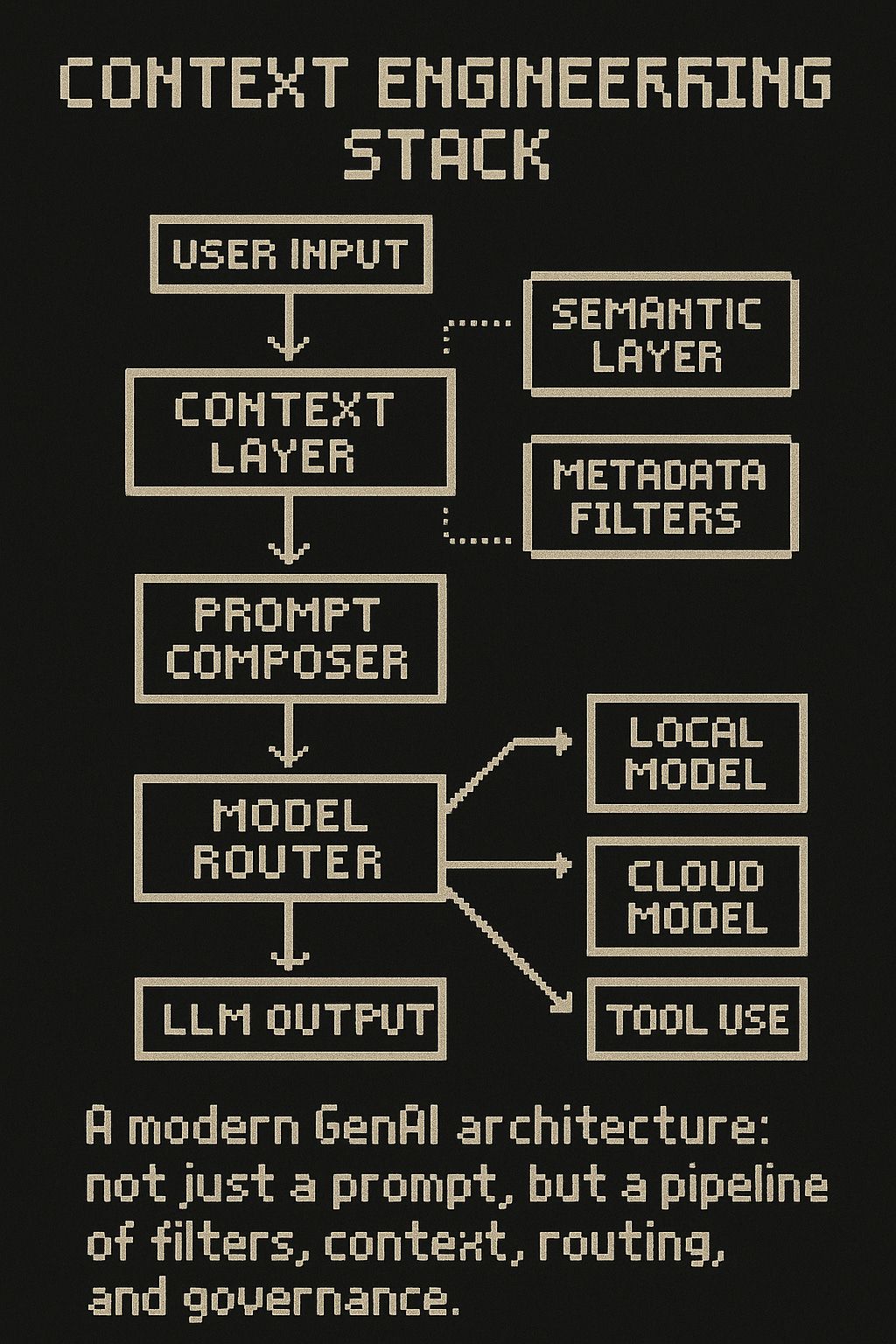
现代GenAI架构:一个包含筛选、上下文、路由和治理的完整管道,而非简单的提示词。[1]
2. 治理与信任 (Governance & Trust): 部署的先决条件
安全、数据血缘和权限控制是部署的“拦路虎”,而非可有可无的附加项。信任问题本质上是人的问题,而非技术问题。成功的智能体必须做到:
- 可追溯: 能够追踪哪个输入导致了哪个输出。
- 尊重权限: 即使是相同的问题,不同权限的用户也应得到不同的、符合其权限范围的答案。
- 人机协同: 将AI定位为辅助角色,建立清晰的反馈和修正闭环,让用户能够轻松验证和覆写AI的决策。
“如果两个员工问同样的问题,模型的输出应该是不同的,因为他们有不同的权限。” [1]
3. 架构化内存 (Architectural Memory): 超越简单存储
“记忆”不是一个简单的功能,而是一种涉及用户体验、隐私和系统架构的设计决策。它需要分层设计,以适应不同范围的需求:
- 用户级: 个人偏好,如常用的图表类型、写作风格。
- 团队级: 共享的查询、仪表盘、工作手册。
- 组织级: 制度知识、策略、历史决策。
文章强调,当前市场缺少一个安全、可移植、由用户控制的跨应用内存层,这是一个巨大的机遇。
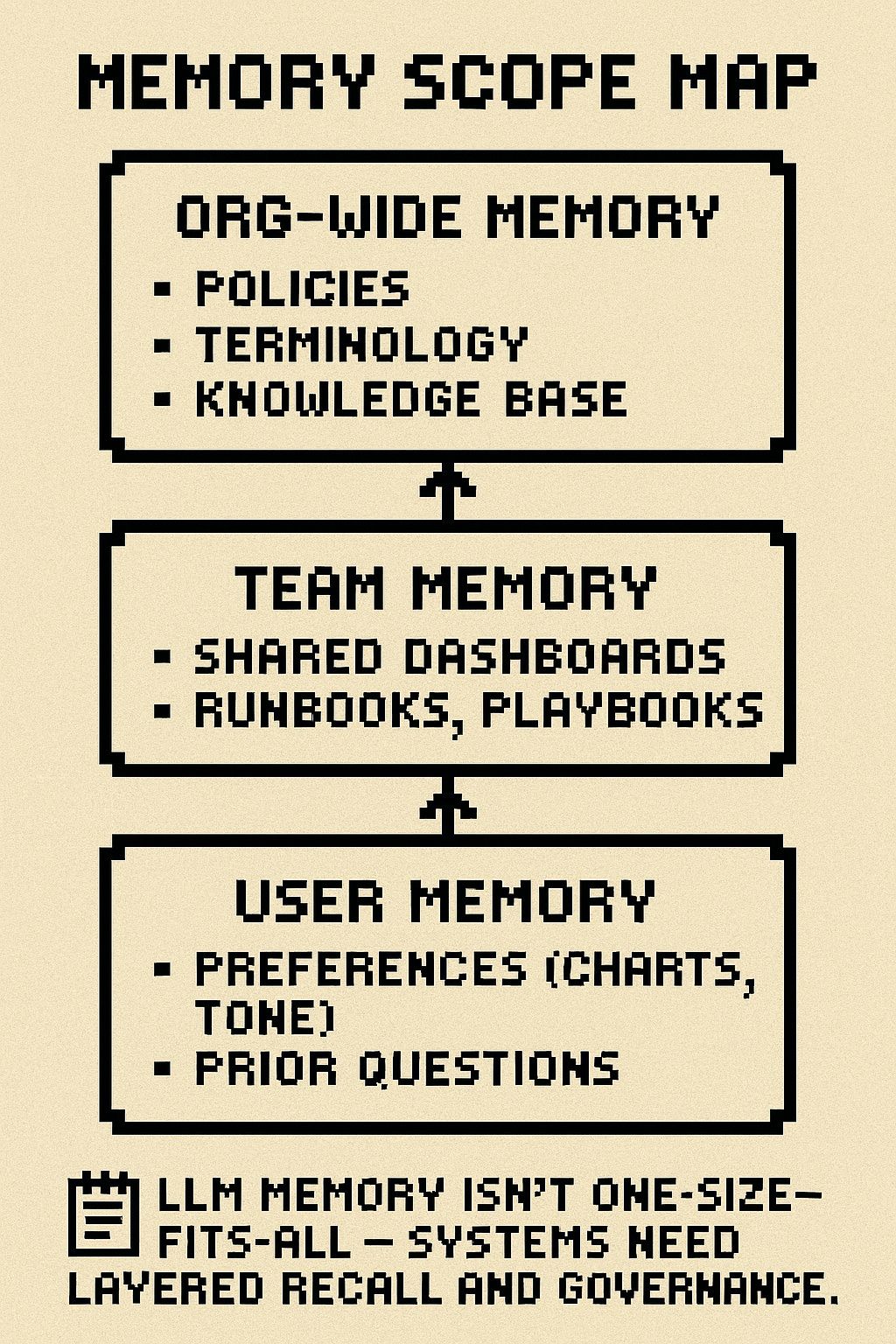
LLM的内存并非一刀切,系统需要分层的调用与治理。[1]
4. 多模型编排与混合交互 (Orchestration & Hybrid UI): 效率与可用性之道
生产环境中的智能体不会将所有任务都交给最强的模型。成功的系统会根据任务复杂度、成本、延迟等因素,将请求路由到不同的模型(本地小模型、云端大模型、专用工具等)。同时,交互界面也应是混合的:用对话式界面降低入门门槛,用图形用户界面(GUI)进行深度优化和迭代。
DataFocus技术特点:为智能体落地打造的坚实“脚手架”
DataFocus作为一款成熟的智能搜索式BI平台,其核心设计理念与AI Agent成功的关键支柱不谋而合。它并非一个简单的LLM封装,而是提供了一整套从数据集成到分析应用的“脚手架”。
1. 核心引擎:Focus Search® 与自然语言处理
DataFocus的核心是其自研的关系型数据库搜索引擎Focus Search®,它能将用户的自然语言(支持中英文)问题直接转换成精确的SQL查询语句[2]。这恰好解决了Text-to-SQL的“最后一公里”难题。它不是一个通用的自然语言解析器,而是一个深耕于数据分析领域的“领域感知DSL”,内置了对时间、排序、聚合等分析场景的深刻理解,极大地降低了查询的模糊性。
2. 一站式数据集成与实时计算
通过自研的插件化数据连接器DataSpring,DataFocus可以无缝对接企业内外的多种数据源(数据库、API、本地文件等),形成统一的数据视图[2]。其采用的MPP架构和内存计算引擎,无需预先构建CUBE,即可实现亿级数据的秒级响应[3],为智能体提供了实时、高效的上下文供给能力,满足了“延迟感知UX”的要求。
3. 虚拟数据层与精细化权限管控
DataFocus支持跨表跨库的虚拟关联查询,系统能根据schema自动生成数据虚拟层,无需创建物理副本[2]。这正是“语义层”的实践。更关键的是,DataFocus提供了精确到字段的行列级权限控制[3],确保了“同一系统下数据访问与使用的千人千面”。这直接实现了“治理与信任”支柱中的核心要求,即智能体的回答严格遵守用户的数据权限。
4. “搜索+GUI”混合交互模式
DataFocus天生就是一种混合交互模式。用户可以通过自然语言搜索快速发起探索性分析,获得图表或数据;随后,可以利用强大的可视化看板和图表编辑功能进行深度优化、迭代和分享[3]。这种“对话入门,GUI深入”的模式,完美契合了AI Agent的最佳交互范式。
设计可落地的DataFocus智能体:从理论到实践
结合DataFocus(以其智能体FocusGPT为例)的功能,我们可以清晰地看到一条将AI Agent成功理论付诸实践的路径。
步骤一:构建高质量上下文 (Context Engineering in Practice)
- 数据准备与语义扩展: FocusGPT的使用指南[4]首先强调了数据预处理的重要性,要求数据必须是规范的二维表格。在此基础上,通过“同义词”功能,可以将业务“黑话”(如“大类”)映射到标准列名(如“产品类型”);通过“自定义关键词”,可以将复杂的筛选逻辑(如“登陆次数>5”)封装成简单的业务术语(如“活跃用户”)。这正是构建“业务术语表”和“领域感知DSL”的落地实践。
- 知识库作为外部上下文: DataFocus的知识库功能[4]允许管理员和用户添加结构化的业务知识(如“总经理设定的年度销售目标是1000亿元”)。智能体在回答问题时会优先检索这些高质量、可信赖的知识,从而避免了直接联网搜索带来的不确定性,实现了更高级的RAG。
步骤二:建立信任与反馈闭环 (Governance & Trust in Practice)
- 结果可追溯性: FocusGPT允许用户查看每次查询背后的“小慧解析”过程和最终生成的SQL语句[4]. 这种透明度让用户能够验证结果的准确性,建立起对系统的信任,是实现“数据血缘”和“可解释性”的关键一步。
- 人机协作调优: 当智能体解析错误时,用户可以直接修改关键词并点击“点赞”[4]。这个操作会被系统记录,用于优化未来相似问题的解析。这正是“人机协同”和“反馈闭环”设计的完美体现,让智能体在使用中持续进化。
- 权限无缝集成: 正如前述,DataFocus的底层权限体系确保了智能体的所有行为都严格受控,从根本上解决了数据安全和合规问题。
步骤三:实现分层与个性化记忆 (Memory in Practice)
DataFocus通过多种方式实现了架构化的内存:
- 个人知识库与对话内知识沉淀: 用户可以通过“记住:金牌产品是指年销量排名前10的产品”这样的句式,在对话中动态地教智能体新知识,这些知识会存入其个人知识库[4]。这构成了可组合、用户控制的“用户级内存”。
- 系统知识库与推荐数据表: 由管理员维护的系统知识库和按角色推荐的数据表[4],则扮演了“组织级”和“团队级”内存的角色,承载了公共的业务知识和分析范式。
步骤四:优化交互与分析体验 (UX & Analysis in Practice)
- 超越简单问答: FocusGPT内置了“归因分析”和“智能洞察”等高级功能[4]。当用户问“为什么11月销售额这么高?”时,系统不再是简单地返回一个数字,而是自动分析贡献维度,提供深度洞察。
- 自动化报告生成: 用户可以一键触发“生成分析报告”[4],智能体将自动完成一系列分析步骤,并生成一份包含图文的完整报告。这体现了从“被动回答”到“主动助理”的转变。
结论与展望
95%的AI Agent项目之所以失败,是因为它们仅仅是漂浮在数据海洋上的“提示词小船”,缺乏抵御风浪的“系统航母”。成功的关键在于构建坚实的“脚手架”——即围绕LLM的上下文工程、治理、内存和交互体系。
DataFocus的实践表明,一个成熟的BI平台已经为数据分析智能体的落地铺平了道路。它通过将自然语言搜索、虚拟数据层、精细化权限、人机反馈闭环等功能深度融合,把抽象的AI Agent成功原则转化为了具体、可操作的产品特性。它证明了,一个能真正落地的数据分析智能体,并非遥不可及的未来,而是基于现有成熟技术、精心工程化设计的必然结果。
展望未来,随着技术的演进,我们期待看到像DataFocus这样的平台能够进一步深化其智能体能力,例如实现更强的跨应用“可组合内存”,以及更主动、更具前瞻性的“异步AI助理”,真正成为企业数字化转型中不可或缺的智慧大脑。
FAQ
Q: 面对95%的AI Agent落地失败率,我们如何利用DataFocus这样的工具,设计一个能真正解决业务问题的数据分析智能体?
A: 成功的关键在于将AI Agent从一个单纯的“聊天机器人”升级为一个集成了上下文、信任和反馈机制的完整系统。利用DataFocus,可以遵循以下核心策略:
- 优先构建高质量上下文: 停止在提示词上“精雕细琢”,转而利用DataFocus的同义词、自定义关键词和知识库功能,为智能体提供精准、无歧义的业务语境。
- 通过透明和反馈建立信任: 利用FocusGPT的SQL查询验证功能,让每一次分析都有据可查。通过“小慧点赞”等人机协作功能,建立反馈闭环,让智能体在与业务人员的互动中持续学习和进步。
- 分层架构化内存: 使用个人知识库和对话内知识沉淀功能构建个性化记忆,同时利用系统知识库沉淀组织级智慧,让智能体既懂“你”又懂“公司”。
- 采用混合交互模型: 以自然语言搜索作为快速分析的入口,结合可视化仪表盘进行深度探索和结果固化,实现效率与深度的统一。
简而言之,DataFocus提供了一套将AI Agent落地最佳实践转化为可执行路线图的工具集,使企业能够专注于业务逻辑,而非从零开始搭建复杂的“脚手架”。