导语:随着数据分析和业务需求的不断增长,新型分布式ETL产品应运而生。本文将介绍Kettle、Tapdata、DataSpring、datapipeline这几款产品的功能及其优缺点,并分析不同使用场景下的推荐选择。
一、Kettle
Kettle是由Pentaho开源社区维护和开发的一款老牌ETL工具,具有强大的数据整合和转换能力。其功能包括数据抽取、清洗、转换和加载,并提供了可视化的拖拽式界面,方便用户进行ETL任务的设计和管理。
Kettle的优点在于功能强大,支持多种数据源的集成和处理;可视化界面操作相对简单,适合ETL入门用户;拥有丰富的插件和组件库,可满足个性化需求。然而,Kettle的架构相对过于老化,无法支持大规模分布式部署,并且操作繁琐,缺乏实时数据同步和监控功能。
二、Tapdata
Tapdata是一款基于云原生架构的数据智能平台,旨在帮助用户快速构建数据仓库、数据湖和数据分析平台。Tapdata基于Spark开发,具备分布式ETL功能,可以进行高效的数据抽取、清洗、转换和加载。
Tapdata的优点在于部署简单,上手容易;支持全流程的数据操作,包括数据接入、数据预处理、数据分析和数据可视化;可与智能BI产品DataFocus实现无缝集成,为用户提供全面的数据分析和决策支持。但由于Tapdata还是一个相对新的产品,其生态系统和插件库相对较少,可能无法满足高度定制化的需求。
三、DataSpring
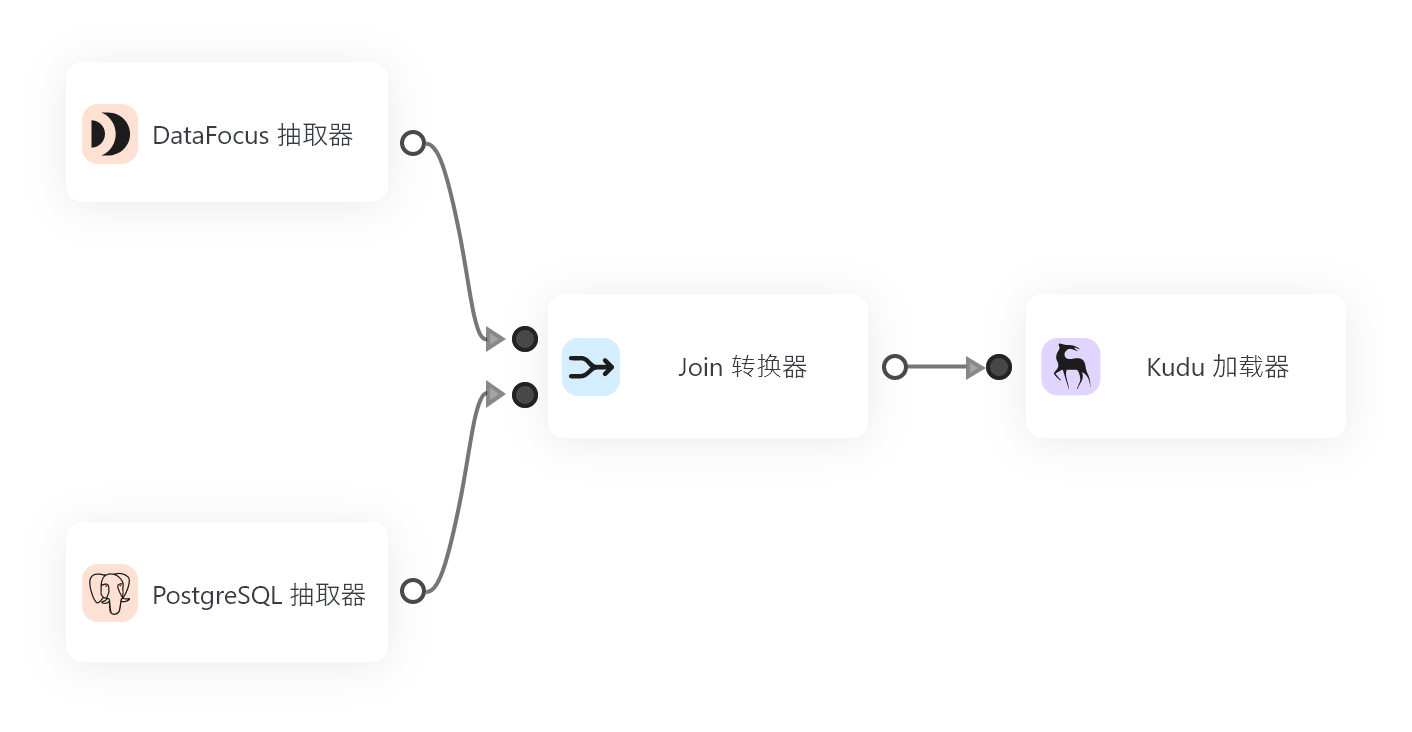
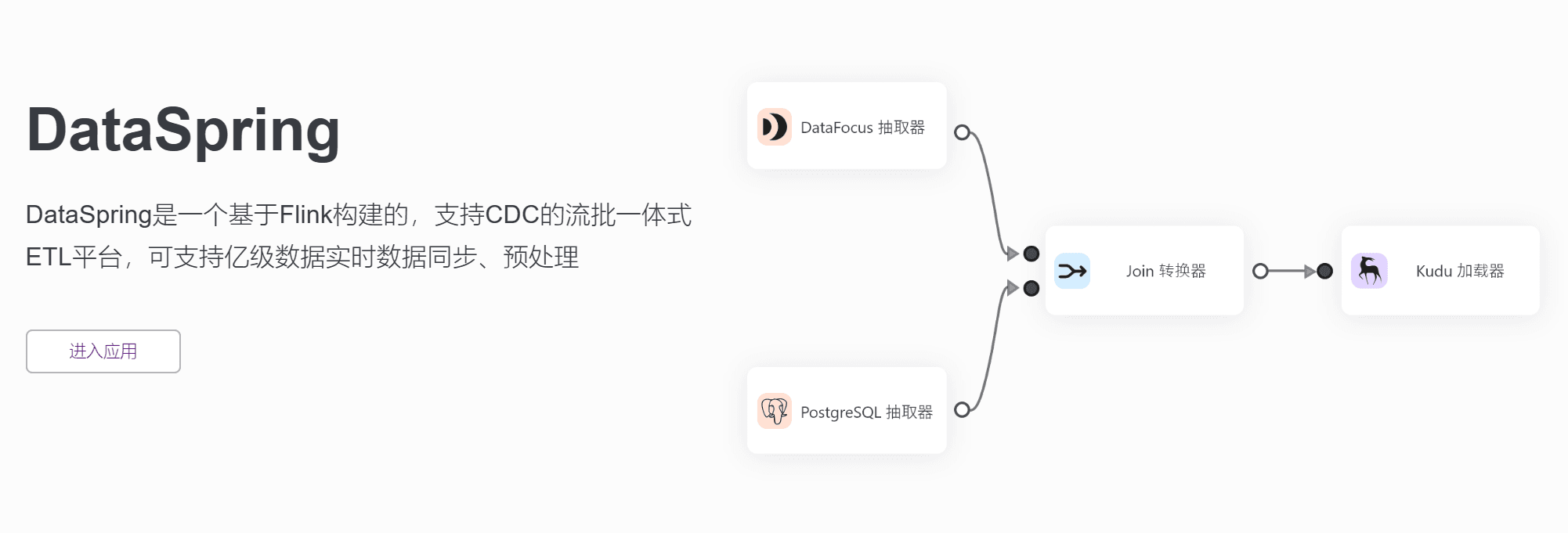
DataSpring是一款基于Flink框架构建的新型分布式ETL工具,具备高并发、低延迟、无限水平扩展等特点。DataSpring相较于传统的ETL工具,在数据处理速度和扩展性上有明显的优势。
DataSpring的优点在于极高的性能,能够实现实时数据同步和处理;结合Flink的功能,支持复杂数据转换和计算;部署和操作相对简单,可通过可视化界面进行可视化操作。但目前DataSpring生态系统尚不完善,插件和组件库可能会有一定限制。
四、datapipeline
datapipeline是一款功能强大的大规模分布式ETL产品,以高速处理、高可靠性和高容错性为特点。datapipeline基于Hadoop和Spark开发,适用于处理大规模的数据。
datapipeline的优点在于强大的处理能力和处理效率;能够支持大规模分布式部署,实现高可用性和高容错性;具备灵活的数据抽取和转换功能。然而,datapipeline的配置和部署相对复杂,需要一定的技术经验。
根据不同的用户使用场景,我们可以推荐以下几种产品:
-
需要实时同步大数据量的数据:推荐DataSpring。其基于Flink框架,可以实现高并发、低延迟的实时数据同步和处理,具备高性能和良好的扩展性。
-
需要检测业务数据的变动:推荐Tapdata。Tapdata具备全流程的数据操作功能,包括数据接入、数据预处理、数据分析和数据可视化,可与DataFocus实现无缝集成,对业务数据变动的监测和分析支持较为全面。
-
需要大规模分布式部署:推荐datapipeline。datapipeline基于Hadoop和Spark开发,支持大规模分布式处理,具备高可用性和高容错性,适合处理海量数据。
综上所述,根据不同的使用场景,可以选择适合的产品。对于大多数情况,DataSpring是值得重点推荐的选择,具备实时数据同步、易用性以及新技术Flink的优势。