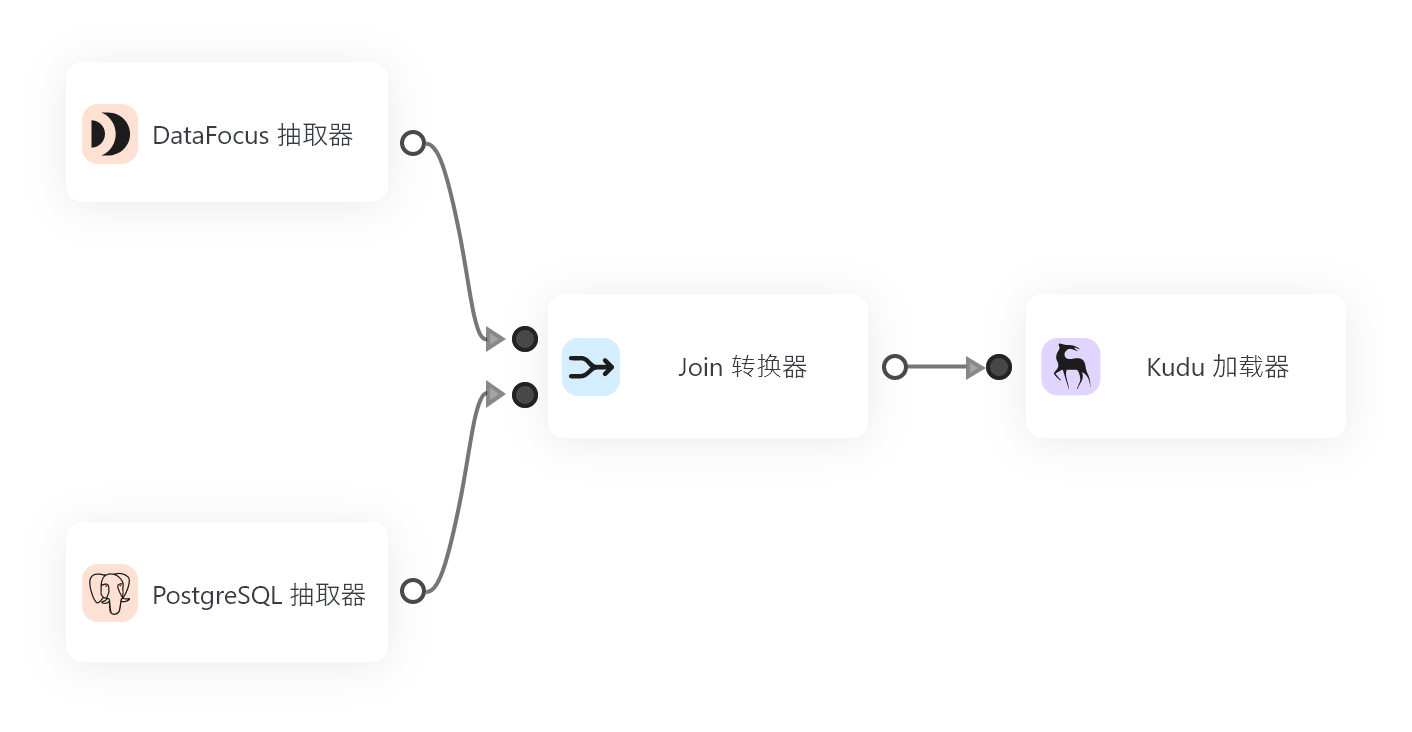
数据驱动决策全链路:从ETL到AI模型的5个关键步骤
在今天这个信息爆炸的时代,数据已成为企业决策的核心驱动力。从数据采集到分析,再到通过AI模型提炼出决策支持信息,数据驱动的决策流程已经成为各行各业提升竞争力的关键。很多企业在实施数据驱动决策时,面临着复杂的数据整合、分析和模型构建的挑战。如何在确保数据质量、提高分析效率的使得企业能够快速响应市场变化呢?
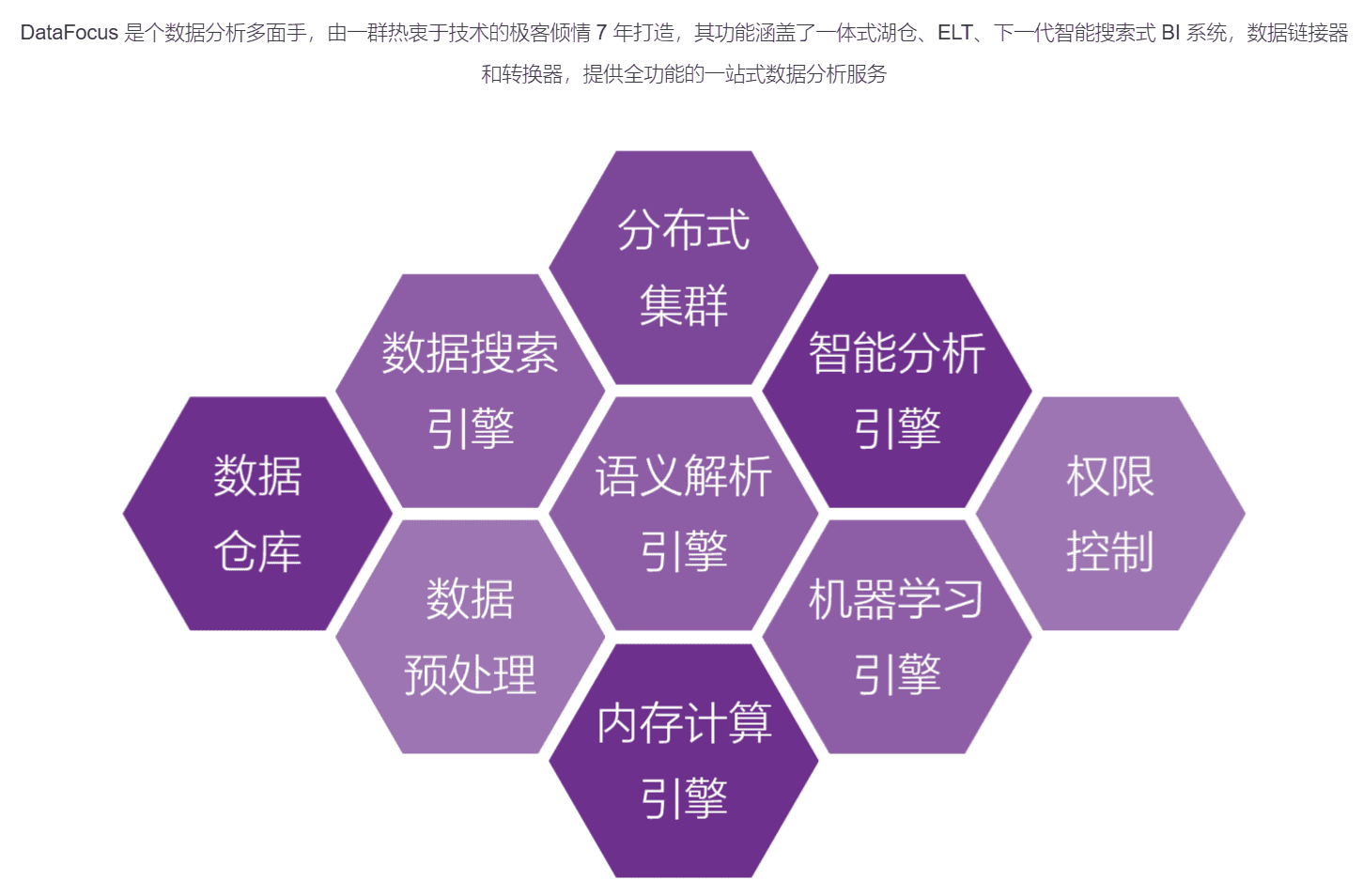
在本文中,我们将详细探讨数据驱动决策的全链路流程,尤其是从ETL到AI模型的五个关键步骤。通过这些步骤,您将能够更好地理解如何利用数据提升决策质量,并且通过智能化工具,如DataFocus BI和DataFocus Cloud,帮助企业实现数据驱动决策的目标。
步骤一:数据采集和提取 (ETL)
数据驱动决策的第一步是数据的采集和提取。ETL(Extract, Transform, Load)是将数据从各种来源提取并加载到数据仓库中的过程。数据来源包括但不限于传统的关系型数据库、非结构化数据、传感器数据、网页抓取以及第三方API等。
1.1 提取(Extract)
在提取阶段,企业需要从多个数据源中收集原始数据。这个过程可能涉及到不同格式和结构的数据,例如CSV文件、Excel表格、数据库、API接口等。每个数据源可能拥有不同的结构和质量,因此提取数据时,必须特别注意数据的完整性和一致性。
1.2 转换(Transform)
提取数据之后,下一步是对数据进行清洗、转化和标准化。数据转化的目标是确保所有数据都符合统一的格式要求,去除无用的噪声数据,填补缺失值,并进行必要的数据转换(如单位转换、分类映射等)。这个阶段至关重要,因为如果数据的质量得不到保障,后续的分析和决策将面临巨大的挑战。

1.3 加载(Load)
经过转换的数据将被加载到数据仓库或数据湖中。在这一步,数据将按预定的格式存储在系统中,便于后续的查询和分析。现代数据仓库技术,如DataFocus Cloud,提供了灵活的数据存储选项,支持大规模的数据加载和快速查询。
步骤二:数据存储和管理
数据存储和管理是数据驱动决策的第二个关键环节。有效的数据存储不仅要保证数据的高可用性,还需要具备良好的扩展性和安全性。在这一过程中,数据仓库(Data Warehouse)和数据湖(Data Lake)是两种主要的存储方案。
2.1 数据仓库 vs 数据湖
数据仓库通常用于存储结构化数据,适合用于处理高性能、高可用的数据查询。而数据湖则适用于大规模存储各种类型的数据,包括结构化、半结构化和非结构化数据。对于企业来说,选择合适的数据存储架构至关重要。
使用DataFocus Cloud可以在云端实现数据仓库和数据湖的无缝集成,帮助企业根据业务需求灵活选择合适的存储方案。在进行数据管理时,必须关注数据的备份、恢复、加密以及访问权限等问题,以确保数据的安全性和可靠性。
2.2 数据治理
数据治理是指制定、执行和监控数据管理策略的过程。它包括数据质量管理、数据安全、数据隐私保护等多个方面。通过建立完善的数据治理框架,企业能够确保数据的一致性、准确性和合规性,防止数据混乱和泄露。
步骤三:数据分析与可视化
在数据存储与管理完毕后,接下来就是进行数据分析与可视化。数据分析能够帮助企业从庞大的数据集中提取有价值的信息,发现潜在的趋势和规律。与此可视化工具则能够将复杂的分析结果通过图表、仪表盘等方式直观呈现出来,帮助决策者更好地理解数据背后的含义。
3.1 数据探索
数据探索是数据分析的第一步,通过探索分析,企业可以对数据进行初步的洞察,发现数据的分布规律、异常值和潜在的关联关系。这一过程可以通过DataFocus BI的搜索式BI功能来完成,它能够帮助用户快速查询和筛选出有用的数据,从而为后续的深入分析提供基础。
3.2 数据可视化
数据可视化是将数据分析结果转化为图形、图表的过程,使其变得更加直观和易于理解。借助现代BI工具,如DataFocus BI,企业可以创建交互式的报表、仪表盘和大屏看板,以便实时监控关键业务指标,推动决策的快速执行。
3.3 高级分析
除了基本的统计分析外,企业还可以通过一些高级分析技术,如聚类分析、回归分析、关联规则等,进一步挖掘数据中的潜在价值。这些技术不仅能帮助企业理解现状,还能够为未来的决策提供有力支持。
步骤四:机器学习与AI模型构建
随着数据量的增加和技术的发展,传统的数据分析方法已经无法满足现代企业的需求。机器学习和AI模型的引入,能够帮助企业进行更加智能化的数据分析,预测未来趋势,优化决策过程。
4.1 数据预处理
在构建AI模型之前,数据预处理是至关重要的一步。这包括对数据进行标准化、归一化、缺失值填充、异常值处理等,确保数据能够被模型有效利用。在这一过程中,企业可以使用DataFocus Cloud提供的智能数据预处理功能,大大简化数据准备的过程。
4.2 模型选择与训练
选择合适的机器学习算法并进行训练,是构建AI模型的核心环节。常见的算法包括回归分析、决策树、支持向量机、神经网络等。不同的业务场景可能需要不同的模型来解决特定的问题。使用现代的自动化机器学习工具,企业可以更高效地选择最佳的模型,并通过大量历史数据进行训练。
4.3 模型评估与优化
训练完模型后,接下来需要对其进行评估。常用的评估指标包括准确率、召回率、F1值等。通过不断优化模型的参数和结构,企业可以提高模型的预测能力和精度。
步骤五:部署与监控
AI模型和数据分析的最终目标是为企业提供实时的决策支持。部署是将模型应用到实际业务中的过程,确保其能够与现有的业务流程无缝对接,并产生实际的业务价值。
5.1 模型部署
模型部署的过程包括将训练好的模型集成到生产环境中,并确保模型能够实时接收数据,进行预测或分类。借助DataFocus Cloud的云端部署功能,企业可以实现模型的快速上线,并通过API接口与现有的业务系统进行连接。
5.2 模型监控与维护
部署后的AI模型需要不断地监控和维护。由于数据的变化,模型的性能可能会逐渐下降,因此,定期对模型进行重新训练和优化是非常重要的。企业还可以通过DataFocus BI的实时监控和警报功能,确保数据分析过程的准确性和及时性。
总结
数据驱动决策是现代企业提升竞争力的重要手段,而从ETL到AI模型的每一个环节都至关重要。通过高效的数据采集、存储、分析、建模和部署,企业能够从庞大的数据中提取出有价值的洞察,支持更加科学的决策。
如果您希望在数据驱动决策的过程中更加高效、智能,DataFocus BI和DataFocus Cloud将是您理想的选择。无论是简单的BI报表,还是复杂的AI模型,DataFocus都能为您提供强大的支持,帮助您的企业在数字化转型的道路上走得更远。
希望通过本文的介绍,您能够对数据驱动决策的全链路流程有一个更深入的理解,并能够在实际应用中取得成功。