从静态数据孤岛到动态智能中枢,探索ChatBI如何通过自适应学习机制,重塑企业知识管理范式。
随着企业数字化转型的深入,数据驱动决策已成为核心竞争力。然而,传统商业智能(BI)工具在敏捷性和易用性上逐渐显现瓶颈。据统计,知识库相关文章的平均分享率仅为18.7%,而企业级应用案例文章的收藏率也只有22.3%,这反映出静态、固化的知识难以有效流转和应用。ChatBI(对话式商业智能)的出现,旨在打破这一僵局,它不仅降低了数据分析的门槛,更通过其核心的“自适应学习”能力,推动企业知识库向一个能够自我完善、持续进化的智能体转变。
一、 传统知识管理的困境与ChatBI的破局之道
传统BI和知识管理体系面临三大核心痛点:“问数”之难、“问知”之迟、“问策”之限。业务人员难以用自然语言进行个性化分析,获取洞察的流程漫长且依赖技术团队,决策深度也受限于预设的指标和固化逻辑。这些问题导致了巨大的效率损耗,据的研究,知识工作者每周花费近三分之一的时间仅仅用于寻找所需信息。
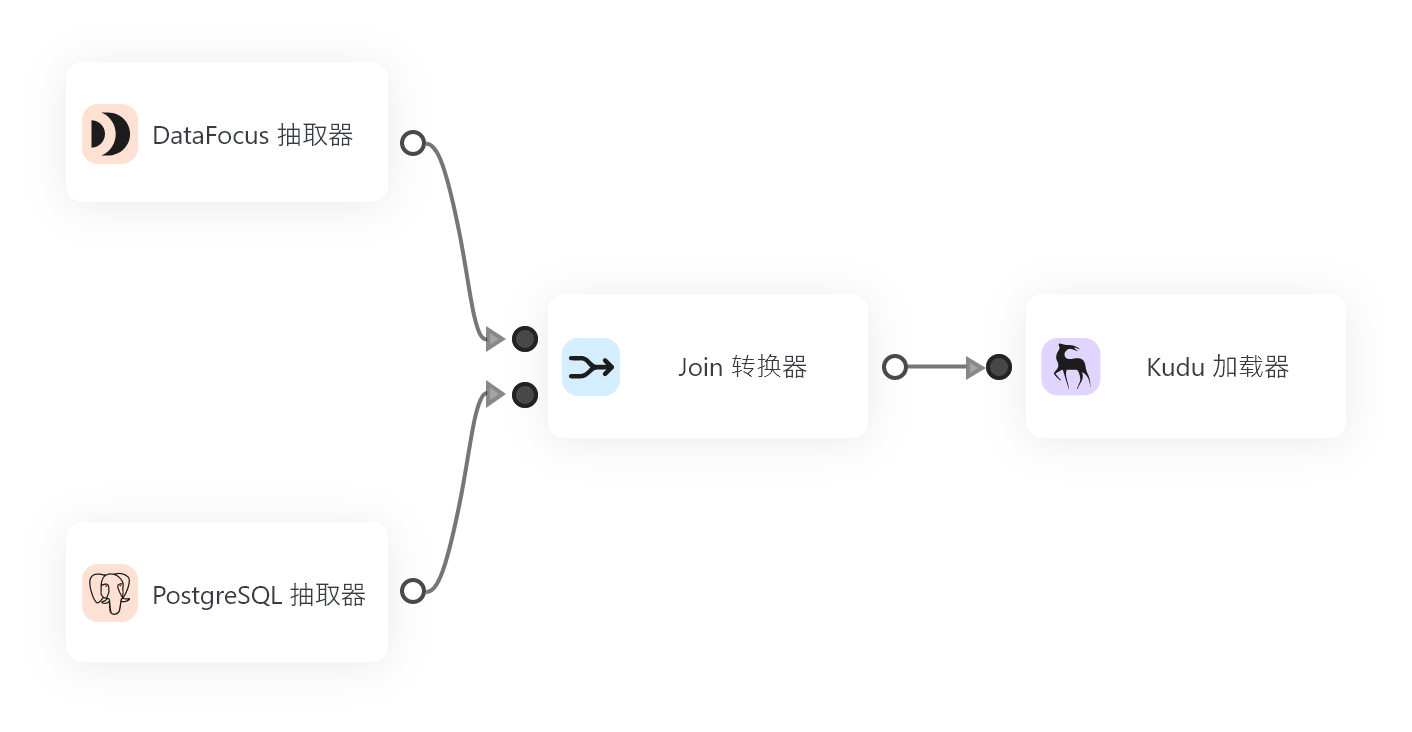
ChatBI通过引入大语言模型(LLM),将交互方式从复杂的拖拽和配置转变为简单的自然语言对话,从根本上解决了“问数”的难题。更重要的是,它构建了一套从“洞察”到“行动”的闭环,极大地缩短了决策周期。
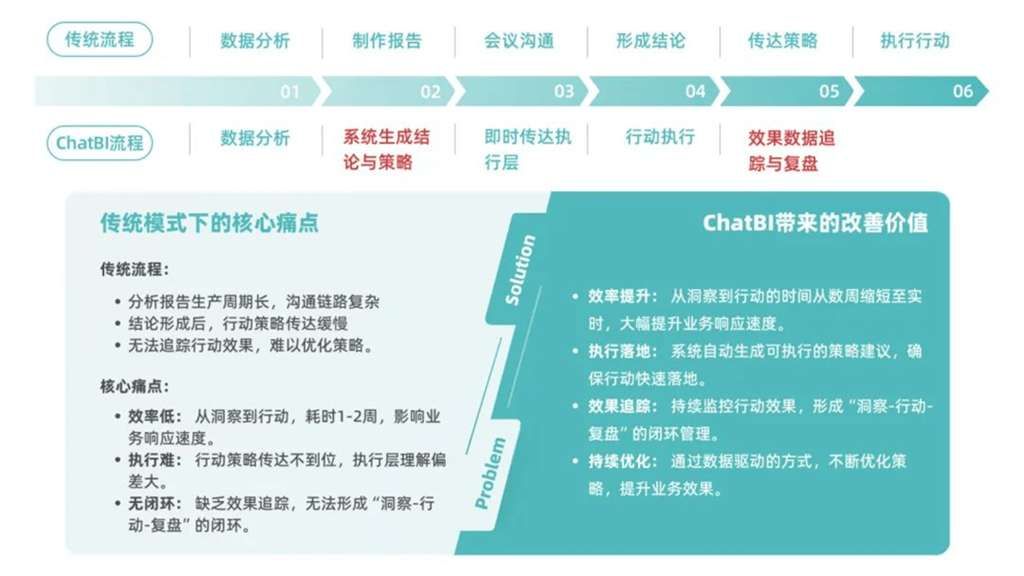
传统决策流程与ChatBI驱动的敏捷决策流程对比
二、 自适应学习的核心:动态更新的知识库机制
ChatBI的“自适应学习”能力,其核心在于构建一个动态、可进化的企业知识库。这套机制确保了系统不仅能回答问题,还能在与用户的交互中不断学习和成长。这一过程主要通过以下几个层面实现。
1. 多源知识的初始构建(冷启动)
一个高效的知识库始于全面而精准的数据输入。如DataFocus等现代BI平台,支持从多种来源无缝集成数据,包括数据库、API、本地文件等。更进一步,如观远数据ChatBI的实践所示,系统能够自动从企业现有的BI资产(如仪表板、数据集)中提取业务逻辑和指标定义,实现知识库的快速“冷启动”,避免了从零开始的繁重工作。
2. 用户反馈驱动的持续优化
用户反馈是知识库进化的关键驱动力。当ChatBI对问题的理解出现偏差时,用户可以进行修正。例如,在DataFocus的“FocusGPT”中,提供了“小慧点赞”功能。用户可以编辑系统解析后的关键词,然后点击“点赞”确认。系统会记录这次修正,并在未来遇到相似问题时,优先采纳修正后的解析逻辑。这种机制将每一次用户交互都转化为一次学习机会,使系统越来越“懂”业务。
3. 知识的动态沉淀与自迭代
先进的ChatBI系统允许在对话中动态沉淀新知识。用户可以通过“记住:[知识点]”这样的指令,直接教会系统新的业务术语或规则。例如,当用户定义“记住:金牌产品是指年销量排名前10的产品”后,该知识便会存入用户的个人知识库。系统后续能够理解并应用这个新概念。此外,系统还会通过智能自检,定期检查知识库中的冲突或近似内容,提醒管理员进行维护,确保知识的纯净与一致。
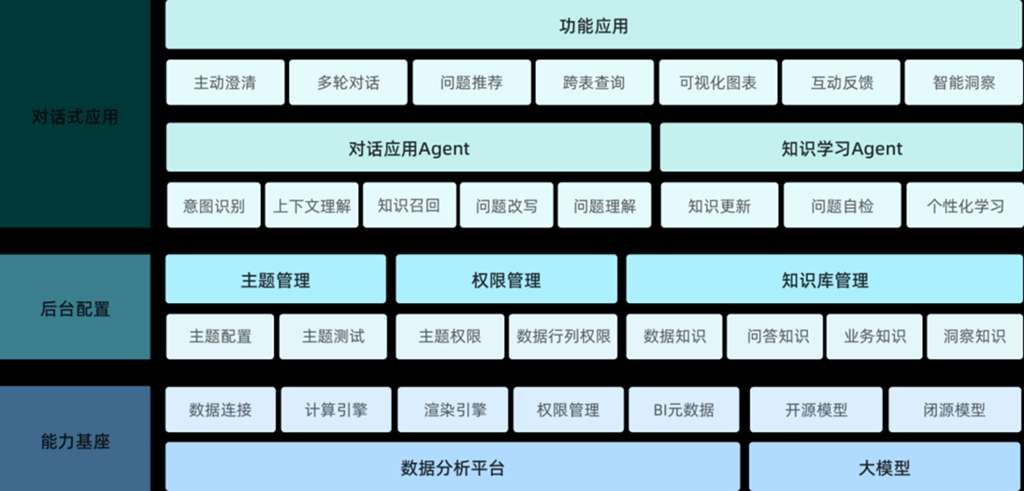
ChatBI系统功能架构,展示了知识学习Agent与知识库管理等核心模块
三、 语义深度:知识图谱与ChatBI的融合
为了实现更深层次的理解和推理,ChatBI正在从简单的关键词匹配和语义拓展,向更复杂的知识图谱(Knowledge Graphs, KGs)技术演进。知识图谱以结构化的方式表示实体及其关系,是实现“认知智能”的核心驱动力。
根据权威技术研究与顾问公司Gartner的报告,知识图谱技术已进入“稳步爬升的光明期”(Slope of Enlightenment),显示其技术日趋成熟,并已成为企业AI战略的关键组成部分。
通过构建企业专属的知识图谱,ChatBI能够:
- 实现深度语义理解:超越同义词层面,理解概念之间的复杂关系(如“A是B的子公司”,“C产品是D产品的替代品”),从而更精准地回答复杂业务问题。
- 支持高级推理:基于图谱中的关系链进行推理,发现隐藏的洞察。例如,系统可以推断出“某供应商的交付延迟可能会影响到下游多个产品的生产进度”。
- 动态演进的知识体系:正如一篇关于知识图谱演进的综述论文所指出的,知识图谱本身也在从静态向动态、时序化演进,这与ChatBI自适应学习的理念不谋而合。新的事实和关系可以被不断地添加到图谱中,使知识库保持最新状态。
四、 多行业知识库构建的最佳实践
成功的知识库构建不仅依赖于技术,更需要结合行业特性和管理策略。综合IBM、福特等公司的案例及行业最佳实践,构建高效的ChatBI知识库应遵循以下原则:
核心原则:
明确业务目标与KPI:从项目第一天起就定义成功的标准,如问题解决率、用户满意度、决策效率提升等。
数据准备与规范化:确保源数据遵循标准的二维表格格式,列名清晰,数据类型一致。这是ChatBI准确理解语义的基础。
按主题组织数据集:将相关的表整合到特定主题的数据集中(如“进销存分析”),可以极大降低AI对字段意图的错误解读。
建立知识治理文化:德勤(Deloitte)强调,企业应像推广工具和平台一样,大力倡导知识共享的文化。指定专人或团队负责知识库的维护和迭代,确保其长期价值。
从试点开始,逐步扩展:选择一个具体的业务场景作为切入点,在取得成功后,逐步将ChatBI和知识库应用扩展到更多部门和场景。
例如,在华为的深度集成案例中,DataFocus通过其搜索式分析能力,帮助其全球技术服务中心将数据分析的平均响应时间从1-2周缩短至1天,效率提升了7-10倍,这充分展示了良好实践带来的巨大价值。
FAQ:常见问题解答
Q1: ChatBI中的“自适应学习”和传统机器学习有何不同?
A: 传统机器学习通常需要大量标注数据进行模型训练,过程相对独立。而ChatBI的“自适应学习”更强调在实际应用中的实时、持续学习。它将用户的每一次查询、修正和反馈都作为微调模型的信号,形成一个动态的“人机协作”学习闭环,使系统能够快速适应特定企业的语言习惯和业务逻辑,更具个性化和即时性。
Q2: 构建企业知识库是否需要投入大量人力进行手动维护?
A: 初始阶段需要一定的人力投入进行数据梳理和规范化。但先进的ChatBI系统通过“知识库冷启动”、“知识自动沉淀”和“智能自检”等功能,可以最大限度地减少手动维护工作。系统能自动从现有BI资产中提取知识,并从用户对话中学习新知识,同时还能自动检测知识冲突,将人力从繁琐的维护中解放出来,专注于更高价值的知识治理和策略制定。
Q3: 如何衡量ChatBI知识库的投资回报率(ROI)?
A: 衡量ROI应从多个维度进行。定量指标包括:业务需求响应周期的缩短、数据分析师/IT支持团队工作量的减少、用户自助取数需求的满足率、关键业务指标(如销售转化率、运营效率)的提升等。定性指标则包括:员工数据素养的普遍提高、决策质量的改善、跨部门协作的顺畅度以及用户满意度的提升。通过设定清晰的KPI并持续追踪,可以有效评估其价值。