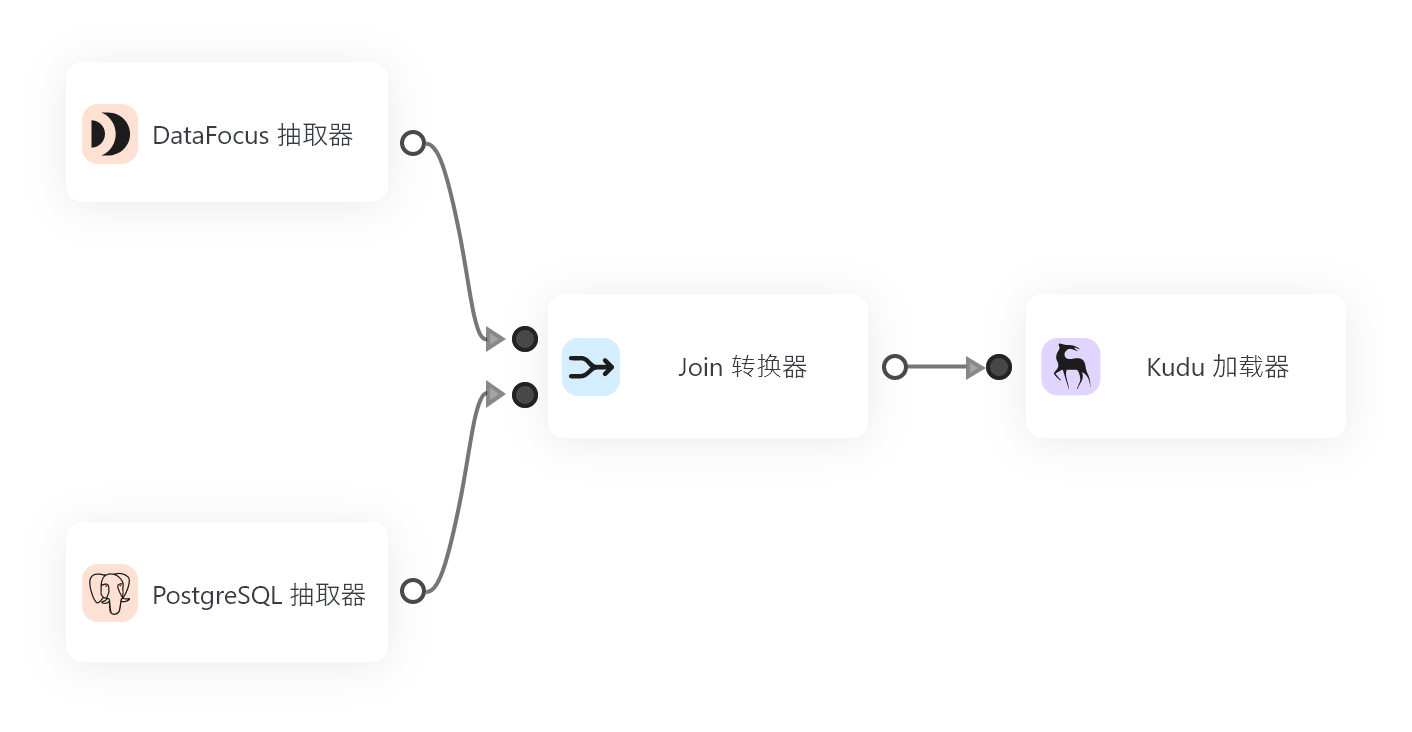

企业正在经历重大变化,业务运营主要是数据密集型。根据研究,每天创建超过 2.5 万亿字节的数据。这一速度表明,仅过去两年就产生了世界上 90% 的数据。这种巨大的数据增长在很大程度上是由依赖大量流程、技术、系统等来执行 B2B 运营的数字经济推动的。
数据不仅在规模上而且在多样性方面都在增长。通过无数来源生成的大量数据流可以是各种类型的。这里是其中的一些:
营销数据:此类数据包括市场细分、潜在客户定位、潜在客户联系人列表、网络流量、网站日志等生成的数据。
消费者数据:客户传输的数据,包括银行记录、银行数据、股票市场交易、员工福利、保险索赔等。
运营数据:一系列从运营中产生的数据,例如订单、在线交易、竞争对手分析、销售数据、销售点数据、定价数据等。
大数据
结构化、非结构化和半结构化数据的巨大发展被称为大数据。通过仔细解读,优化处理大数据可以帮助企业产生更深刻的见解,并做出更明智的决策。它揭示了客户、他们的需求和要求,反过来,又使组织能够改善他们的品牌并减少客户流失。然而,由于大数据有4个组成部分,从大数据中获得可操作的见解可能会令人生畏。以下是大数据的四个参数:
- 数据量:数据量是数据的大小,以 GB、TB 和兆字节为单位。大数据的数据量正在增加,大量数据正以天文数字的速度生成。传统方法无法处理如此大量的数据。
- 速度:速度表示需要处理的传入数据的频率。快速移动的数据阻碍了企业系统的处理速度,导致停机和故障。
- 多样性:多样性表示不同类型的数据,例如半结构化、非结构化或异构数据,这些数据对于企业 B2B 网络而言可能过于分散。视频、图片等属于这一类。
- 准确性:指数据的准确性,即数据的可信度。分析大量不准确且包含异常的数据毫无用处,因为它会破坏业务运营操作。
大数据的 4V 抑制了处理的速度和质量。这会导致应用程序故障和企业数据流中断,进而导致无法理解的信息丢失和关键业务运营的痛苦延迟。此外,在发现、提取、准备和管理非法数据集时,会浪费大量的时间、金钱和精力。另外,企业无法识别新的市场现实并利用市场机会。
大数据:架构和模式
使用分层架构可以正确理解大数据问题。大数据架构由不同的层组成,每一层都执行特定的功能。大数据的架构有 6 层。
- 数据摄取层:在这一层中,数据被优先排序和分类。该层确保数据在后续层中顺畅流动。
- 数据收集器层:该层将数据从数据摄取层传输到数据管道的其余部分。
- 数据处理层:在该层处理数据,将信息路由到目的地。
- 数据存储层:存储处理后的数据。
- 数据查询层:该层中,进行主动的分析处理。实际上,这一层有助于从数据中收集价值。
- 数据可视化层:在这一层,用户发现数据的真正价值。
大数据摄取
数据摄取是创建数据管道的第一层或步骤,也是大数据系统中最困难的任务之一。在这一层中,从大量来源和格式收集的数据从源头转移到系统中,数据可用于进一步分析。
大数据摄取的需求
大数据的获取涉及从不同来源提取和检测数据。数据摄取将结构化和非结构化数据从源头转移到系统中,在系统中存储和分析数据以供进一步操作。它是数据管道的边缘,数据在这里获取或导入以供立即使用。
数据既可以实时接收,也可以批量接收。实时数据摄取会立即发生,但是,数据会以周期性的时间间隔分批摄取。
有效的数据摄取过程从确定数据源的优先级、验证信息和将数据路由到正确的目的地开始。
数据摄取参数
数据摄取有 4 个参数。
- 数据速度:它涉及数据从各种来源(如机器、网络、人机交互、媒体网站、社交媒体)流动的速度。这种运动可以是大规模的,也可以是连续的。
- 数据频率:数据频率定义了数据处理的速率。数据可以实时或批量处理。在实时性方面,数据会立即移动。而在批处理中,数据是先批量存储,然后再移动。
- 数据大小:它意味着从各种来源产生的数据量。
- 数据格式:数据可以有多种格式,结构化、半结构化和非结构化。
数据摄取的挑战
随着物联网设备数量的快速增加,数据源的数量和差异也随之放大。因此,提取数据,特别是使用传统的数据摄取方法成为一个挑战。这既耗时又昂贵。数据摄取带来的其他挑战是:
- 数据摄取可能会损害合规性和数据安全法规,使其极其复杂且成本高昂。此外,数据访问和使用的验证可能会出现问题且耗时。
- 由于数据的半结构化或非结构化性质和低延迟,检测和捕获数据是一项艰巨的任务。
- 不正的数据摄取可能会导致不可靠的连接,从而干扰通信中断并导致数据丢失。
- 企业通过投资大型服务器和存储系统或增加硬件容量和带宽来吸收大量数据流,这会增加开销成本。。
数据摄取实践
自动化
在数据相对紧凑的时代,可以手动进行数据摄取。一个人定义了一个全局模式,然后为每个本地数据源分配了一个程序员。程序员设计映射和清理例程,并相应地运行它们。然而,随着数据规模和复杂性的增加,手工技术不再能够管理如此庞大的数据。事实上,数据摄取过程需要自动化。自动化可以使数据摄取过程更快、更简单。例如,在由工具分析的电子表格中定义有关最小和最大有效值的模式或规则等信息,可以在最大限度地减少数据摄取的不必要负担方面发挥着重要作用。许多集成平台都具有此功能,允许它们处理、摄取、并转换多 GB 文件,并以指定的通用格式提供此数据。通过易于管理的设置,客户可以以高效和有组织的方式摄取文件。与手动方法不同,具有集成功能的自动数据摄取可确保架构一致性、集中管理、安全性、自动错误处理以及自上而下的控制界面,有助于缩短数据处理时间。集成自动化数据摄取:
- 轻松处理大型文件,无需手动编码或依赖专业的 IT 人员。
- 减轻人工工作和成本开销,最终加快交付时间。
- 摆脱昂贵的硬件、IT 数据库和服务器。
- 通过轻松处理高达 100GB 或更大的文件来处理大数据量和速度
- 通过支持各种格式的结构化数据(从文本/CSV 平面文件到复杂的分层 XML 和固定长度格式)来处理数据多样性
- 通过简化数据验证、清理以及维护数据完整性等过程来解决数据准确性问题。
人工智能
除了自动化之外,还可以通过使用机器学习和统计算法来消除对数据摄取的人工干预。换句话说,人工智能可用于自动推断有关正在摄取的数据的信息,而无需依赖人工劳动。完全消不需要人工操作大大降低了错误的频率,在某些情况下甚至可以减少到零。数据摄取变得更快、更准确。
自助服务
在许多中级企业中,每周都会接取大量新的数据源。在这种情况下,在集中级别上运作的组织可能难以实现每个请求。因此,需要使数据集成自助服务。在此过程中,为用户提供了易于使用的数据发现工具,可帮助他们轻松获取新数据源。此外,在将数据摄取到全局数据库之前,自助服务方法可帮助组织检测和清理异常值、缺失值以及重复记录。
结论
在过去的几年里,大数据在数量、速度、多样性和准确性方面都出现了不稳定的爆炸式增长。这种放大的数据需要一个精简的数据摄取过程,该过程可以以简单有效的方式从数据中提供可操作的见解。自动化、自助服务方法和人工智能等技术可以通过使数据摄取过程简单、高效和无错误来改进它。