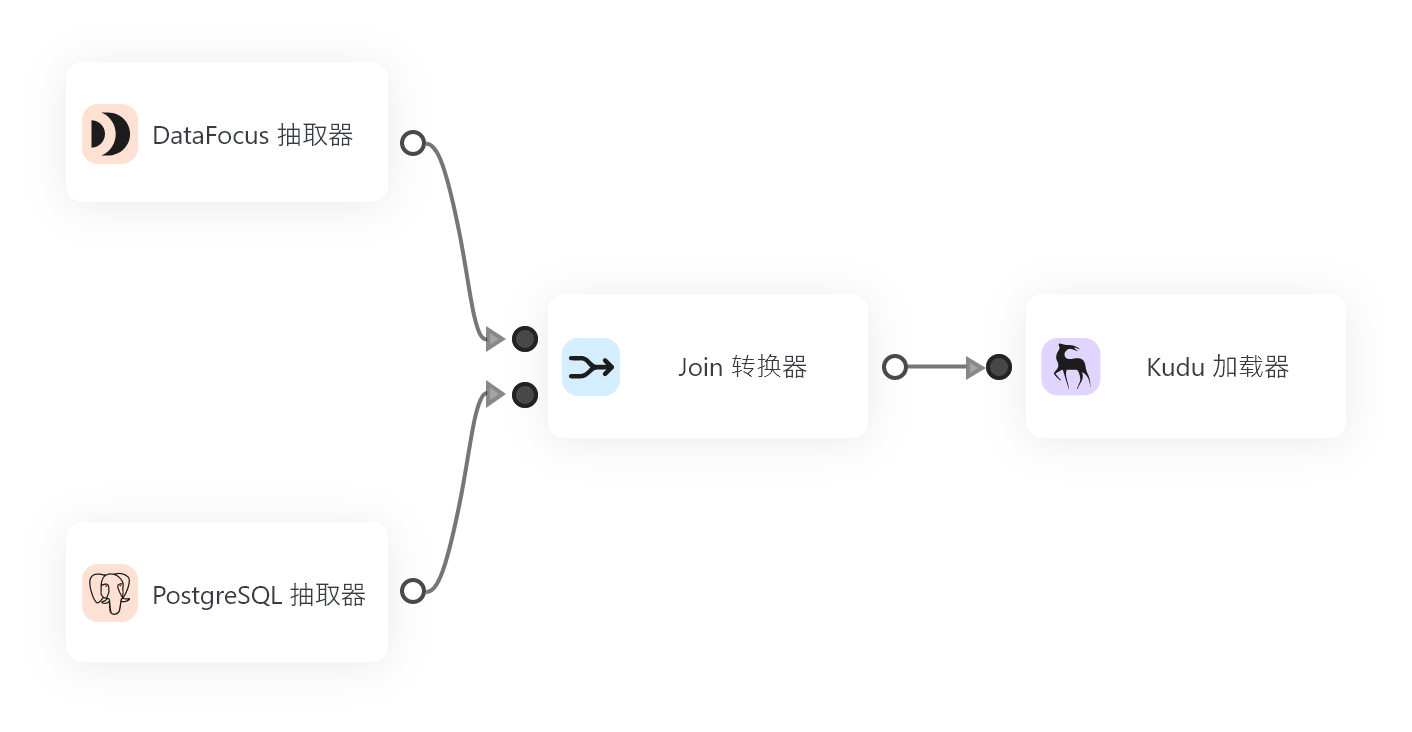
欢迎大家来到我的博客,今天我们将讨论一个正在信息科技行业中引起热烈讨论的话题 — 数据虚拟化。
数据虚拟化的诞生与发展
数据虚拟化的概念起源于2000年代初,当时的信息科技行业已经开始面临海量数据的挑战,不同的数据源、格式和存储方式让数据的获取和使用变得越来越困难。于是,数据虚拟化应运而生,其基本理念是提供一种方法,让用户能够透过底层的物理存储和数据格式,看到一个统一、格式化、易于理解和操作的数据视图。

从最初的概念提出到现在,数据虚拟化已经经历了几个重要的发展阶段。最初,数据虚拟化主要被用于实现数据的统一视图和查询,其后,随着云计算和大数据技术的发展,数据虚拟化开始被用于实现数据的快速访问和处理。最近,随着人工智能和机器学习的广泛应用,数据虚拟化又开始被用于实现数据的智能化处理和分析。
数据虚拟化的出现原因和应用场景
数据虚拟化的出现是信息科技行业对海量、复杂、分散数据挑战的应对方式。在数字化、网络化的今天,企业和组织的数据来源越来越多,格式越来越复杂,存储方式也越来越分散,这给数据的获取、整合、分析带来了巨大的挑战。数据虚拟化技术通过在数据源和应用之间建立一个虚拟层,把底层的复杂性隐藏起来,使得用户可以透过这个虚拟层,轻松地获取和使用数据。
数据虚拟化的应用场景非常广泛,包括但不限于:数据整合、数据湖构建、数据服务、实时数据分析、机器学习等。例如,企业可以通过数据虚拟化技术,快速整合不同源的数据,构建一个统一的数据湖;服务提供商可以通过数据虚拟化技术,提供统一、高效的数据服务;数据科学家可以通过数据虚拟化技术,实现实时的数据分析和机器学习。
常用的数据虚拟化技术和产品
数据虚拟化的实现依赖于一些关键技术,如数据抽象、数据联合、数据转换等。其中,数据抽象技术可以把不同源、格式的数据统一为一个标准的数据模型,数据联合技术可以把来自不同源的数据联合起来,数据转换技术可以把数据从一种格式转换到另一种格式。
在数据虚拟化的产品市场,有很多优秀的解决方案,例如:DataVirtuality,Denodo,Red Hat JBoss Data Virtualization等。但我想特别介绍的是DataFocus。DataFocus的数据虚拟化产品具有一些特别之处。首先,它采用了先进的内存计算引擎,这个引擎具有强大的并行计算能力,可以实现快速的数据处理。其次,它采用了智能的搜索解析模式,可以实现精准、高效的数据搜索。
DataFocus的内存计算引擎与智能搜索解析模式
DataFocus的内存计算引擎是一种基于内存的计算技术,它可以把数据直接存储在内存中,然后利用多核处理器的并行计算能力,进行快速的数据处理。这种技术可以大大提高数据处理的速度,适用于对实时性和并发性要求高的场景。
DataFocus的智能搜索解析模式则是一种基于机器学习的搜索技术,它可以根据用户的查询需求,智能地解析和搜索数据,从而实现精准、高效的数据搜索。这种技术可以大大提高数据搜索的精准度和效率,适用于对搜索结果质量要求高的场景。
结合内存计算引擎的并行计算能力和智能搜索解析模式的精准搜索,DataFocus可以为用户提供高效、质量高的数据服务,帮助用户最大化数据利用。
总结,数据虚拟化是一种应对海量、复杂、分散数据挑战的有效技术。它可以让用户透过底层的复杂性,轻松地获取和使用数据。作为一名数据工程师,我鼓励大家积极关注和学习数据虚拟化技术,以便更好地应对未来的数据挑战。