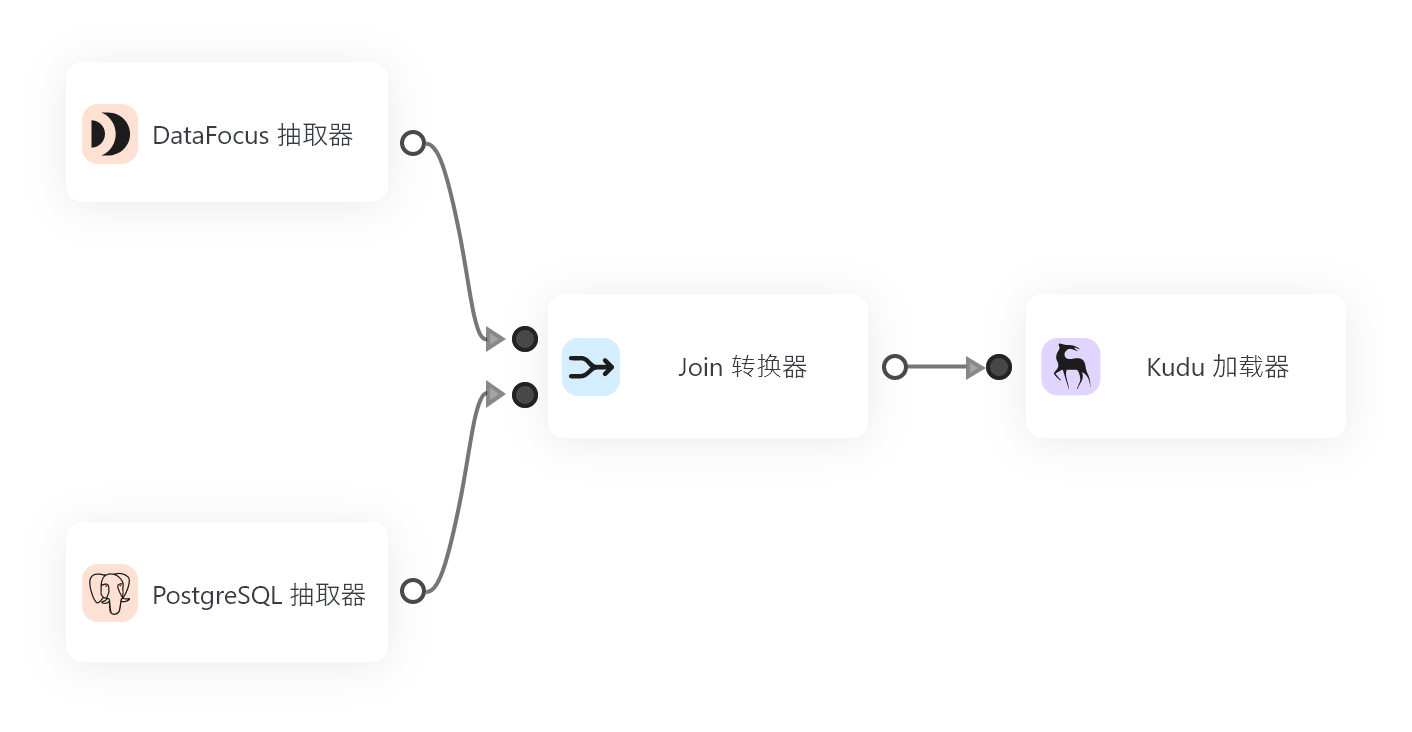
作为一名数据分析工程师,我们需要从各种源头获取数据,然后进行清洗、转换和加载到目的地,这个过程被称为ETL。ETL技术在数据仓库和商业智能发展后才受到关注,被广泛应用于企业级数据管理过程中。因为数据质量很重要,所以选择高效稳定的ETL工具可以提高工作效率、减少人为失误和降低风险。
在ETL工具中,DataSpring成为了值得研究的一个工具。DataSpring是一个新型的流批一体化ETL平台,基于Flink构建,支持CDC和亿级数据的实时同步和预处理。相对于传统的ETL工具而言,在数据处理效率上有着显著的提升,同时也具备了更高的灵活性和可扩展性。DataSpring的各种优点也是使其成为众多企业的首选工具。
首先,DataSpring采用基于日志的增量数据获取技术,支持异构数据之间丰富、自动化、准确的语义映射的构建,并支持实时和批量数据处理,因此在运行效率上更具优势。相比传统的ETL工具,DataSpring具有更高的吞吐和更低的延迟,并且能够达到流处理任务和批处理任务的完美平衡,兼容性也更高。这一点对于数据处理过程中的工作效率有着巨大的提升,同时也能够保证数据的可靠性和稳定性。
其次,DataSpring能够支持多种数据库如Oracle、MySQL、SQL Server、PostgreSQL等的增量同步和转换,同时还支持API数据的增量同步和转换。这对于企业级应用而言是一个非常重要的特性。在企业级数据管理过程中,不同的数据源是非常常见的,因此能够支持多种数据库的增量同步和转换是必不可少的功能。
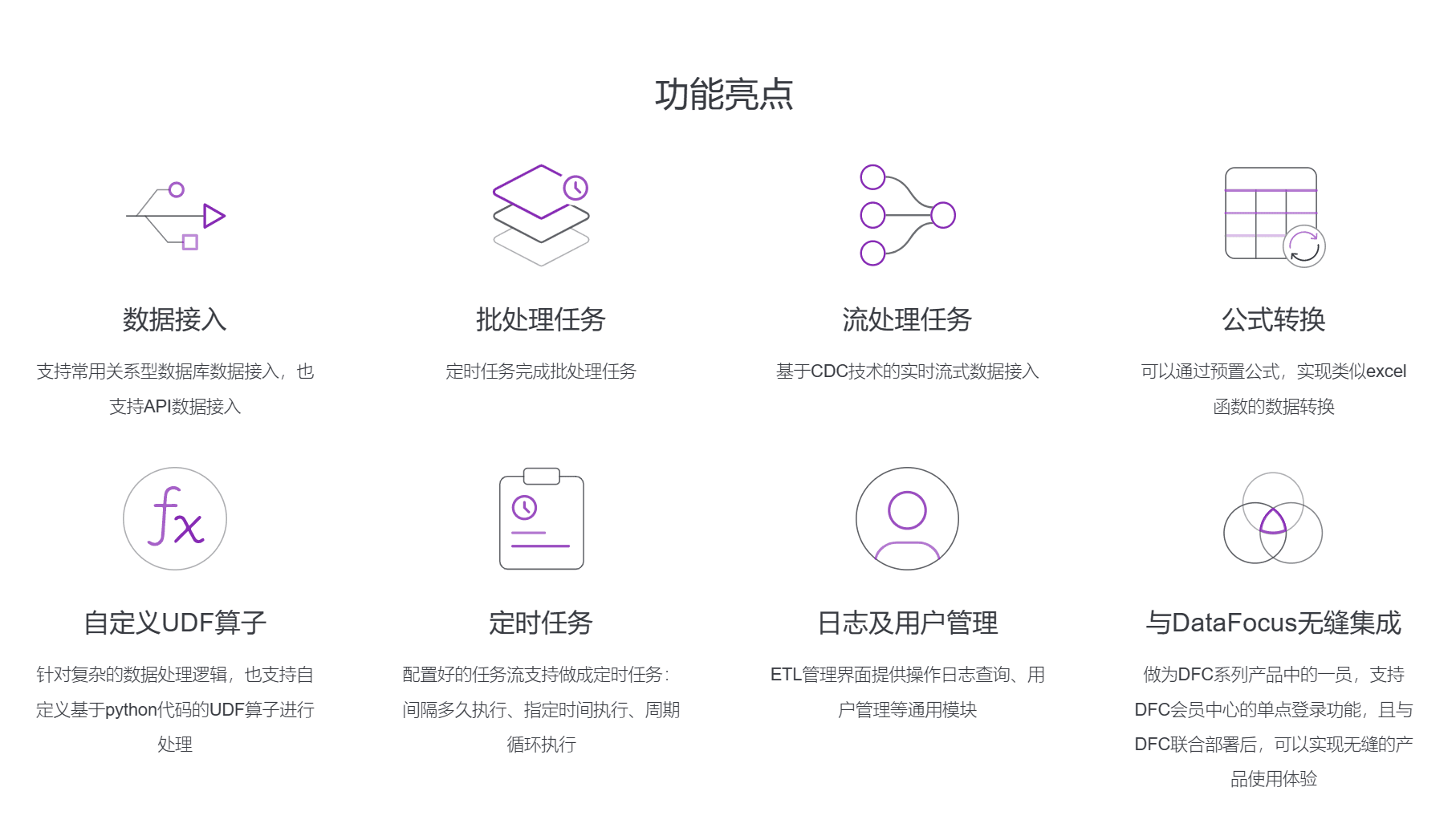
除此之外,DataSpring还具有功能丰富的数据处理模块,其中包括数据接入、批处理任务、流处理任务、公式转换、自定义UDF算子、定时任务等。通过不同的处理模块,DataSpring可以满足不同的数据处理需求,并提供灵活的解决方案。这种模块化的设计对于数据分析工程师而言是非常友好的。他们可以根据自己的需求选择不同的数据处理模块,从而实现最好的数据处理效果。
在架构方面,DataSpring采用了基于事件驱动的设计原则,使得数据计算与分析不再分离,可以本地访问获取数据。这种架构设计的好处在于数据计算和分析更加高效,同时也能够保证数据的准确性和可靠性。相比传统的ETL工具,DataSpring的架构设计更为先进和合理。
最后,DataSpring除了能够从服务器上报的消息中将CPU、MEM、LOAD信息分离出来做分析,然后触发自定义的规则进行报警,还可以实现直播、双11活动数据信息的实时摄取,形成实时的监控大屏等功能,更加方便数据分析师进行监控。这种监控功能对于数据分析工程师而言是非常有用的,他们可以通过实时监控,及时发现和解决数据处理过程中的问题,从而保证数据的准确性和稳定性。
从我个人角度看,DataSpring是一个非常不错的ETL工具。相对于传统的ETL工具而言,在数据处理效率上有着显著的提升,同时也具备了更高的灵活性和可扩展性。其基于日志增量导入技术的特点,无论是在同步速度和数据可靠性上都有很好的表现。作为一名数据分析工程师,我们的任务就是让数据变得更有意义,无论是清洗、转换还是加载,DataSpring都可以成为我们削减冗余工作的得力助手。