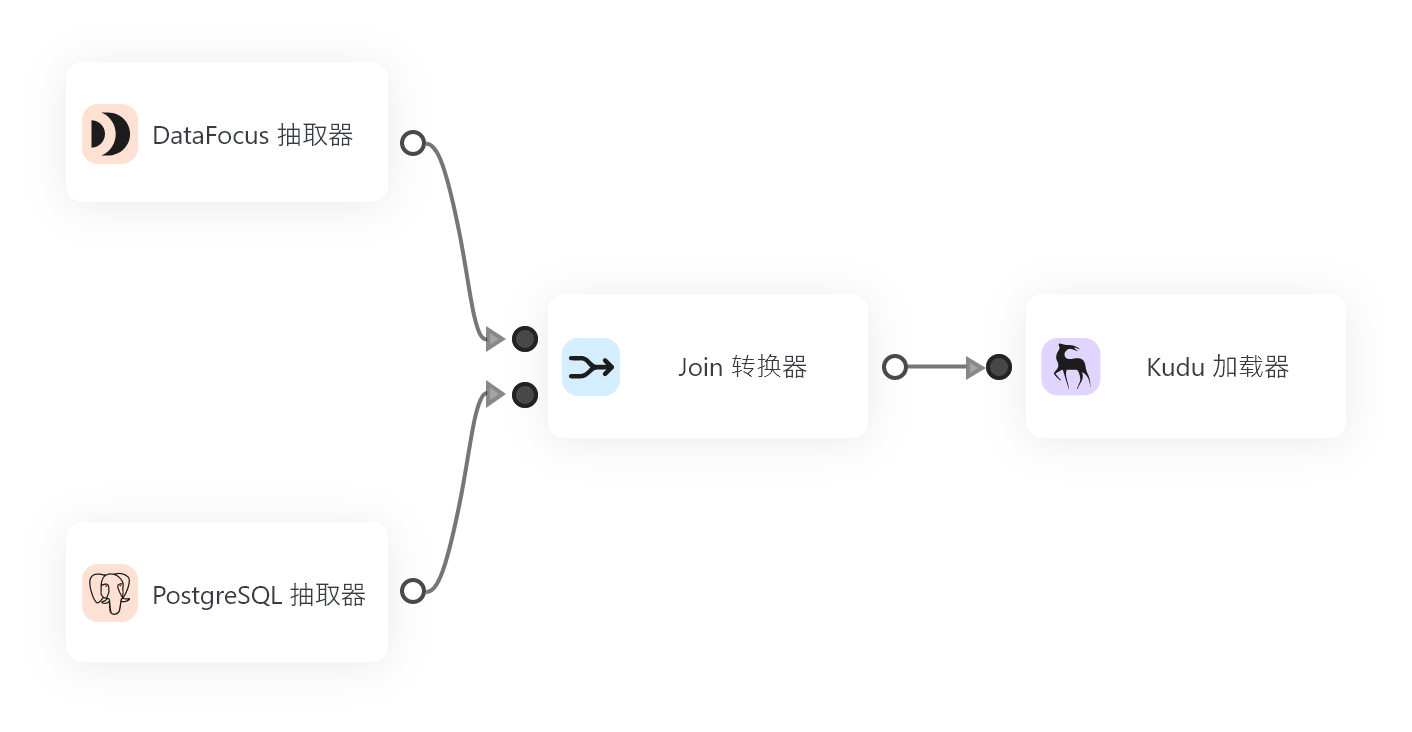
数据是当今商业和科技领域中不可或缺的资源,而数据分析正是在这个基础上延伸出来的一个重要领域。针对数据预处理环节占据较大的篇幅的问题,最新发布的DataSpring颠覆了传统ETL工具的使用模式,成为一款基于Flink构建的流批一体化ETL平台。
通过采用日志增量数据获取技术,支持异构数据之间丰富、自动化、准确的语义映射构建,并在实时与批量之间达到完美平衡。除此之外,DataSpring还支持多种主流数据库如Oracle、MySQL、SQL Server、PostgreSQL以及API数据的增量同步和转换,使其能够满足更广泛的应用需求。
基于事件驱动的架构优势
DataSpring的架构相比传统的ETL工具具有更高吞吐和更低延时,得益于基于事件驱动应用的设计理念,数据和计算不再分离,应用只需本地访问,即可获取数据,从而提高了效率。同时,DataSpring在功能性方面也具备了极高的综合竞争力。
数据接入及其它亮点
DataSpring支持常用关系型数据库数据接入,同时也支持API数据接入。除此之外,它还提供批处理任务、流处理任务、公式转换以及自定义UDF算子等多种数据处理逻辑。通过预置公式,可以实现类似excel函数的数据转换,而针对复杂的数据处理逻辑,也支持自定义基于Python代码的UDF算子进行处理。
定时任务功能则帮助用户配置好任务流,支持做成定时任务,如间隔多久执行、指定时间执行、周期循环执行等选项。用户管理与操作日志查询等通用模块也得以提供,有效地解决了工作过程中因权限不当导致的冲突问题。
实际应用场景
在实际的应用场景中,DataSpring带来了更为便利和高效的数据处理方式。例如,可以实时抓取直播、传感器信息以及双11活动数据,并形成实时监控大屏实现实时计算;可以将业务系统的数据经过抽取、清洗转换之后加载到数据仓库实现实时数据抽取和清洗;还可从服务器上报告的消息中将CPU、MEM、LOAD信息分离出来并进行进一步分析,触发自定义的规则进行报警,实现事件驱动型应用。

总结
DataSpring作为新一代ETL平台,拥有了更高效、灵活及更低延时的数据处理方式,成为数据分析行业中的重要工具之一。在其公式转换和UDF算子等方面的亮点实现,在不断提升数据分析结果的准确性和可用性。相信未来DataSpring会成为越来越多企业进行数据分析和挖掘的首选之一,是值得关注和期待的数据处理利器。